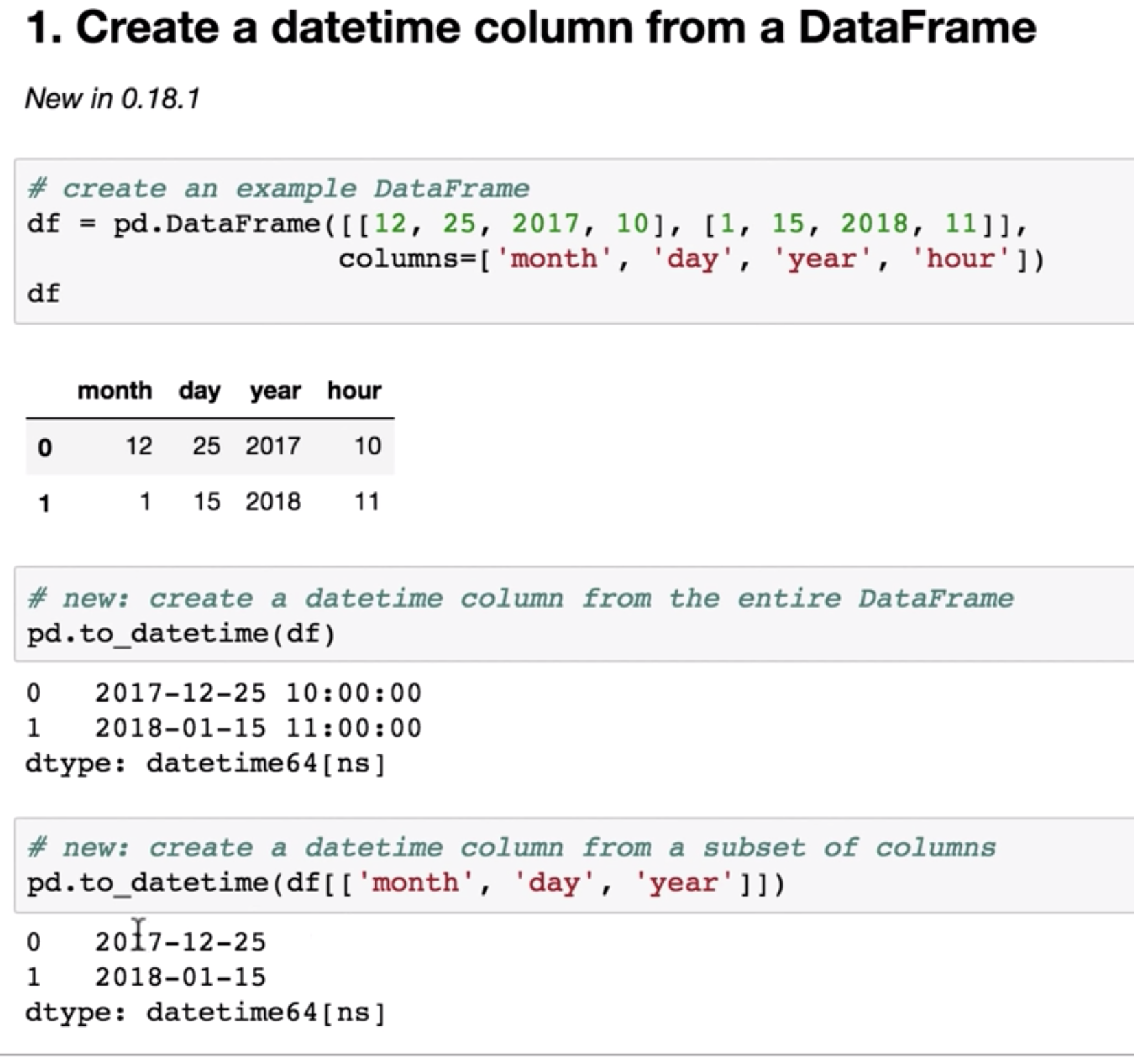
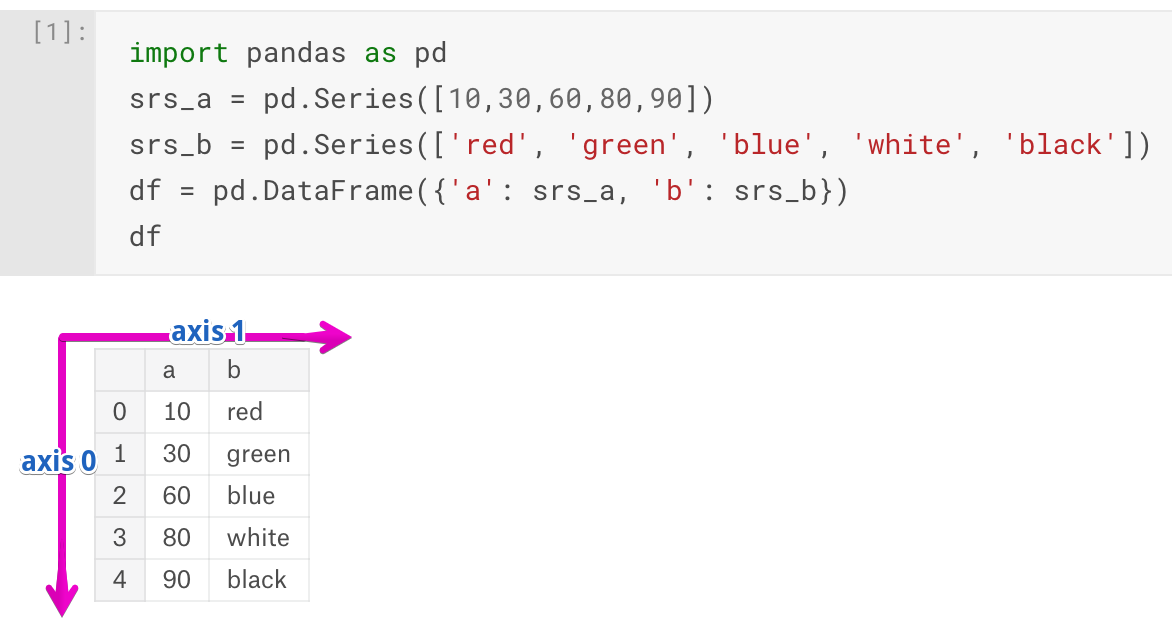
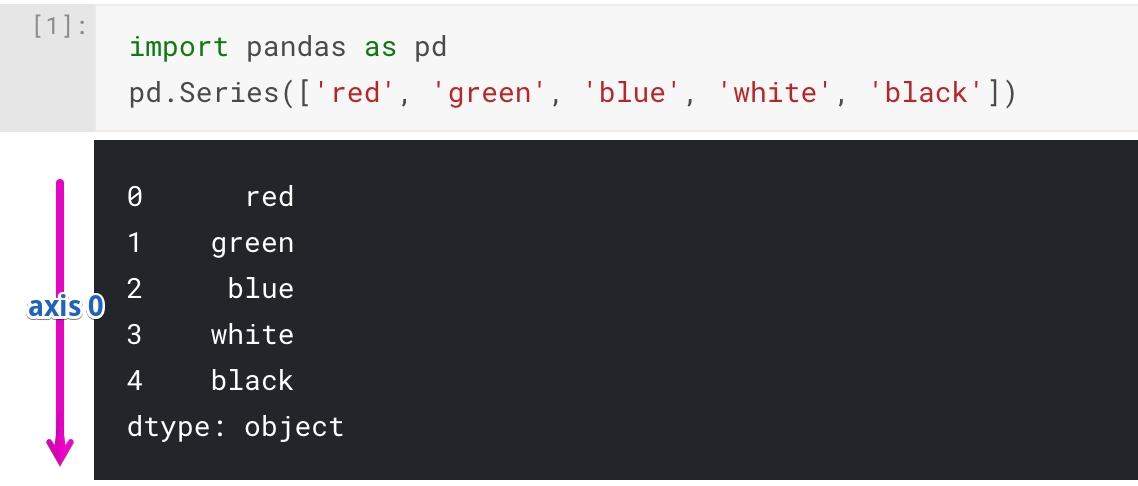
## 转换成DataFrame pd.DataFrame(sndata) > The resulting DataFrame will have its index assigned automatically aswith Series, and the columns are placed insorted order:
#import some file temp = pd.read_csv('../input/train_sample.csv') #do something to the file temp['os'] = temp['os'].astype('str') #delete when no longer needed del temp #collect residual garbage gc.collect()
# https://stackoverflow.com/questions/23330654/update-a-dataframe-in-pandas-while-iterating-row-by-row for row in df.itertuples(): if <something>: df.at[row.Index, 'ifor'] = x else: df.at[row.Index, 'ifor'] = x df.loc[row.Index, 'ifor'] = x
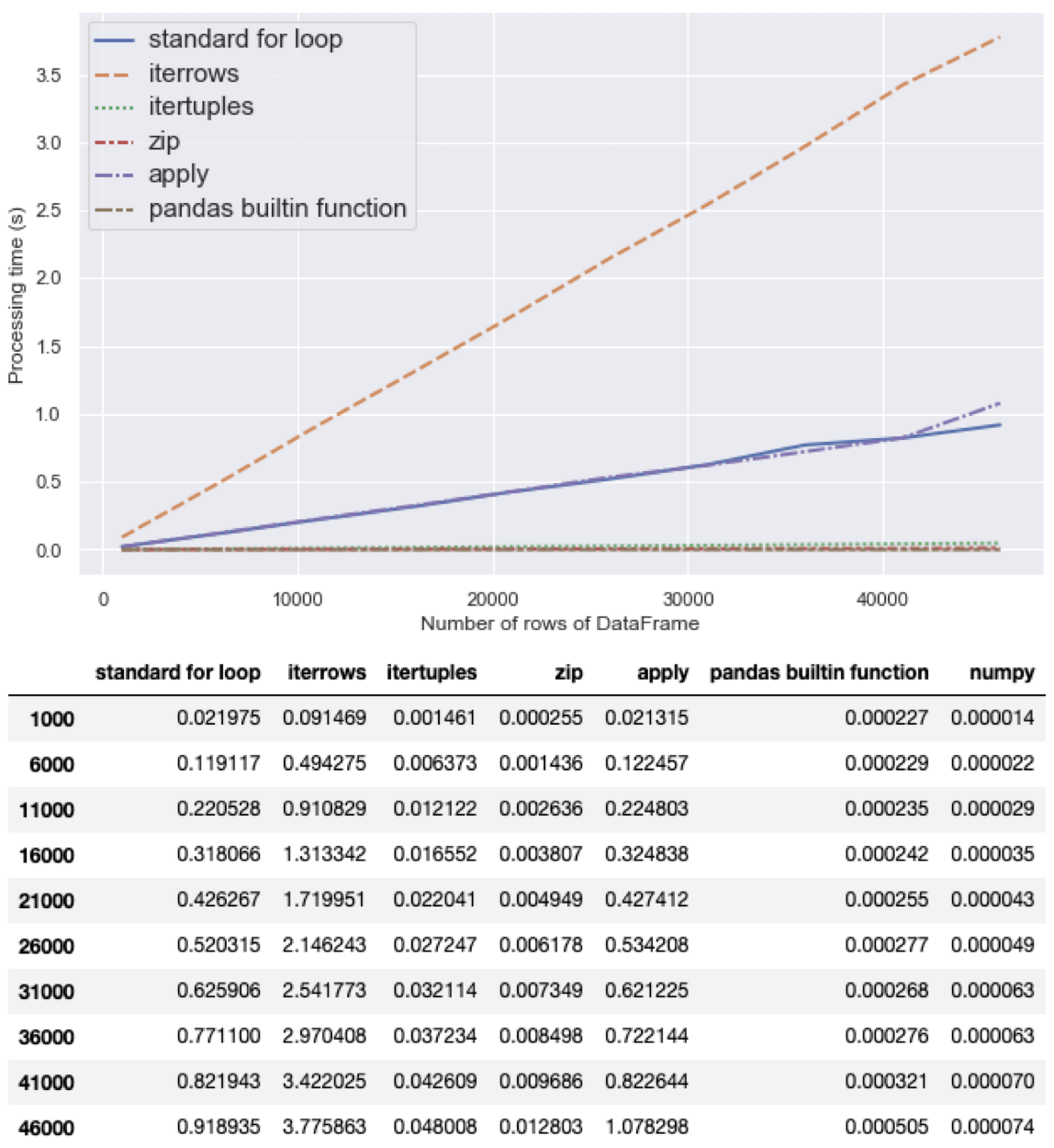
pd.iterrows 的限制
pd.DataFrame.iterrows you are iterating through rows as Series. But these are not the Series that the data frame is storing and so they are new Series that are created for you while you iterate.
# For 循环,iloc 访问 df : 2.65 秒 defloop_with_for(df): temp = 0 for index inrange(len(df)): temp += df['A'].iloc[index] + df['B'].iloc[index] return temp
# For 循环,df.iterrows 访问 df:12.4 秒, 会花费大量时间在 # 创建 series 对象(且不会保留 dtype,如果需要建议使用 itertuples) defloop_with_iterrows(df): temp = 0 for _, row in df.iterrows(): temp += row.A + row.B return temp # For 循环,df.itertuples 访问 df:136 毫秒,终于来到毫秒级别 # 但它还是会创建 namedtuple defloop_with_itertuples(df): temp = 0 for row_tuple in df.itertuples(): temp += row_tuple.A + row_tuple.B return temp
# 实际上,我们可以自己实现,避免创建 nameduple,使用 zip 函数 # For 循环,zip 函数访问,30 毫秒,这里的改进来自于避免创建 namedtuple defloop_with_zip(df): temp = 0 for a, b inzip(df['A'], df['B']): temp += a + b return temp
wide_to_long allows us to set stub names that can group columns.
Remember that wide_to_long() function takes the main arguments: i to set the unique row index, j to set the new variable name, and stubnames to extract the start of the wide columns.
needed to specify the separating elements. When you didn't do that, pandas didn't recognize the column names and returned an empty DataFrame.
Also, wide_to_long() always assumes that suffixes are numeric, so don't forget to specify if they are not!
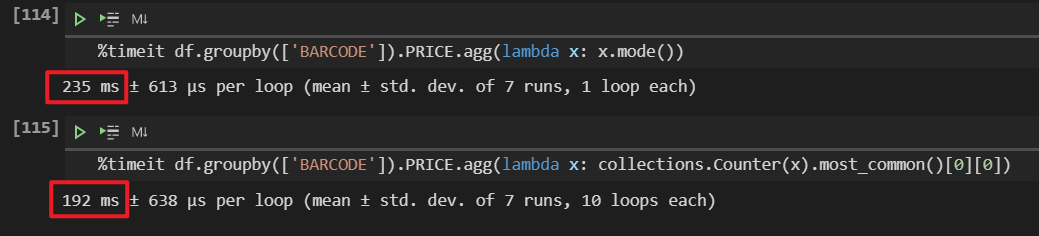
使用 pd.apply
创建列
1 2 3 4 5 6
df['Discounted_Price'] = df.apply( lambda row: row.Cost - (row.Cost * 0.1), axis = 1 ) # Print the DataFrame after addition of new column print(df)
对比 map
1 2 3 4 5
p=pd.Series([1,2,3]) # apply 返回 dataframe,增加两列 a = p.apply(lambda x: pd.Series([x,x+1,x+2])) # map,返回3个 Series a,b,c = p.map(lambda x: pd.Series([x,x+1,x+2]))
Pivot 和 Pivottable
When the .pivot() method finds two rows with the same index and column, but different values for the values, it doesn't know how to handle it.