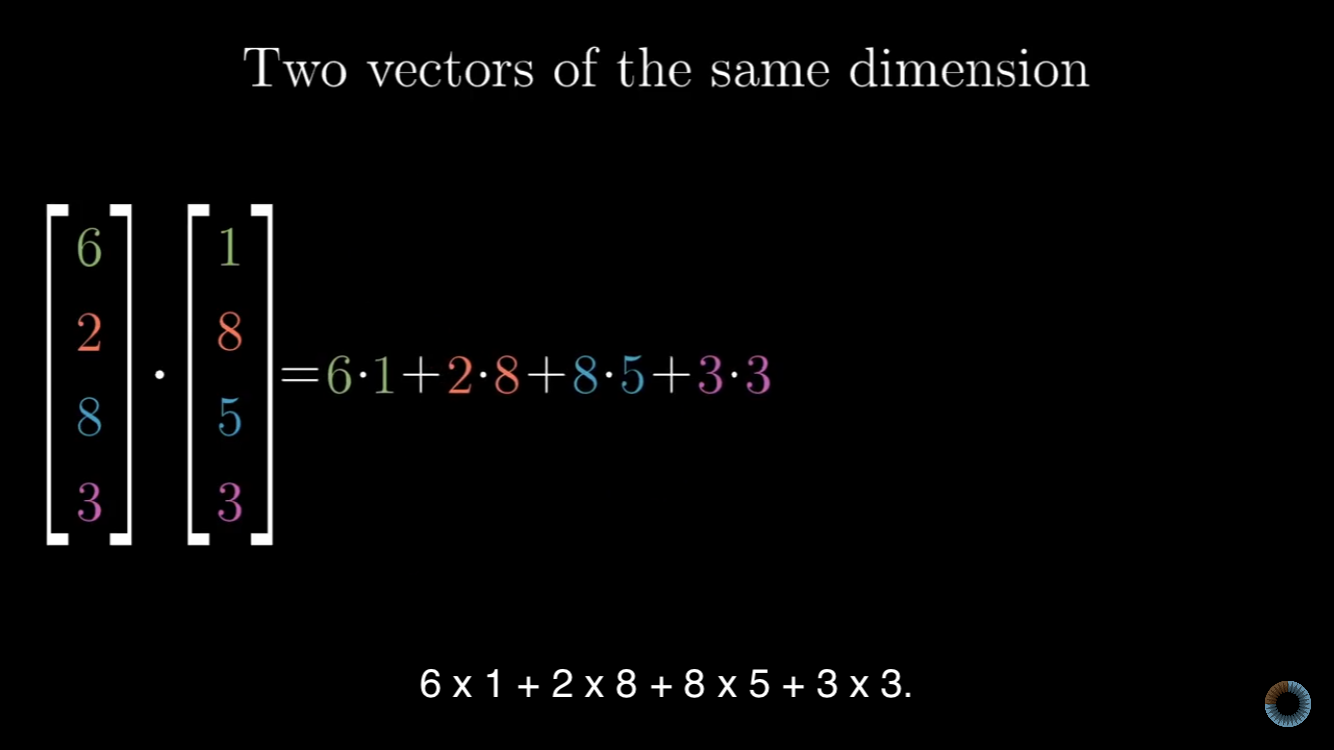> 为什么要使用Numpy?给你两组数据运算,然后对比一下性能就知道了.
> 为什么要使用Numpy?给你两组数据运算,然后对比一下性能就知道了.
Why Numpy?
1 | import numpy as np |
现在对两组数乘以2
1 | %time for _ in range(10): my_arr2 = my_arr * 2 |
Numpy
生成随机数
1 | import numpy as np |
数据长这样:
1 | array([[-0.05094946, -1.54555805, -1.19695135], |
将它们乘10:
1 | array([[ 9.41882893, 3.20674452, 18.05866858], |
两份数据相加:
1 | array([[-2.37617968, 3.45388874, -0.64218591], |
对于Numpy的数据:
An ndarray is a generic multidimensional container for homogeneous data; that is, all of the elements must be the same type. Every array has a shape, a tuple indicating the size of each dimension, and a dtype, an object describing the data type of the array:
- 所有的数据必须是同样的类型
- 每个数组都有一个元组类型的shape属性,表示这个数组的维度信息
- 每个数组都有一个dtype属性用来描述它其中的数据类型
如上面的data:
1 | data.shape ---> (2, 3) |
While it’s not necessary to have a deep understanding of NumPy for many data analytical applications, becoming proficient in array-oriented programming and thinking is a key step along the way to becoming a scientific Python guru.
创建 NDarrays
直接从数组创建:
1 | data1 = [6,7.5,8,0,1] |
也可以从多维数组创建:
1 | data2 = [[1, 2, 3, 4], [5, 6, 7, 8]] |
可以用 ndim 属性来看数组的维度信息。
Numpy还有一些有趣的方法,可以直接创建0和1,或者空值:
1 | np.zeros(10) --> 创建10个0的数组 |
还有一些创建ndarrays的方法:
- array: Convert input data (list, tuple, array, or other sequence type) to an ndarray either by inferring a dtype
- asarray: Convert input to ndarray, but do not copy if the input is already an ndarray
- arange: Like the built-in range but returns an ndarray instead of a list
更多的方法可以参考:Python for data analyse, Table 4-1
NDarrays的数据类型
ndarrays 的data type或者是dtype包含了一些基本的信息(meta),array在定义的时候是可以指定数据类型的,比如:
1 | arr1 = np.array([1,2,3],dtype=np.float64) |
数据类型可以相互转化:
1 | arr = np.array([1,2,3,4]) |
相反的float也可以转化成 int,十进制多出来的部分会被四舍五入。
数组运算
下面是基本的运算:
1 | arr = np.array([[1., 2., 3.], [4., 5., 6.]]) |
乘:
1 | arr*arr |
减:
1 | arr-arr |
所有的运算都是基于相对关系的,记住这一点即可。除此之外,np还支持比较,假设两个arr对比,返回结果会是一个包含true或false的数组。
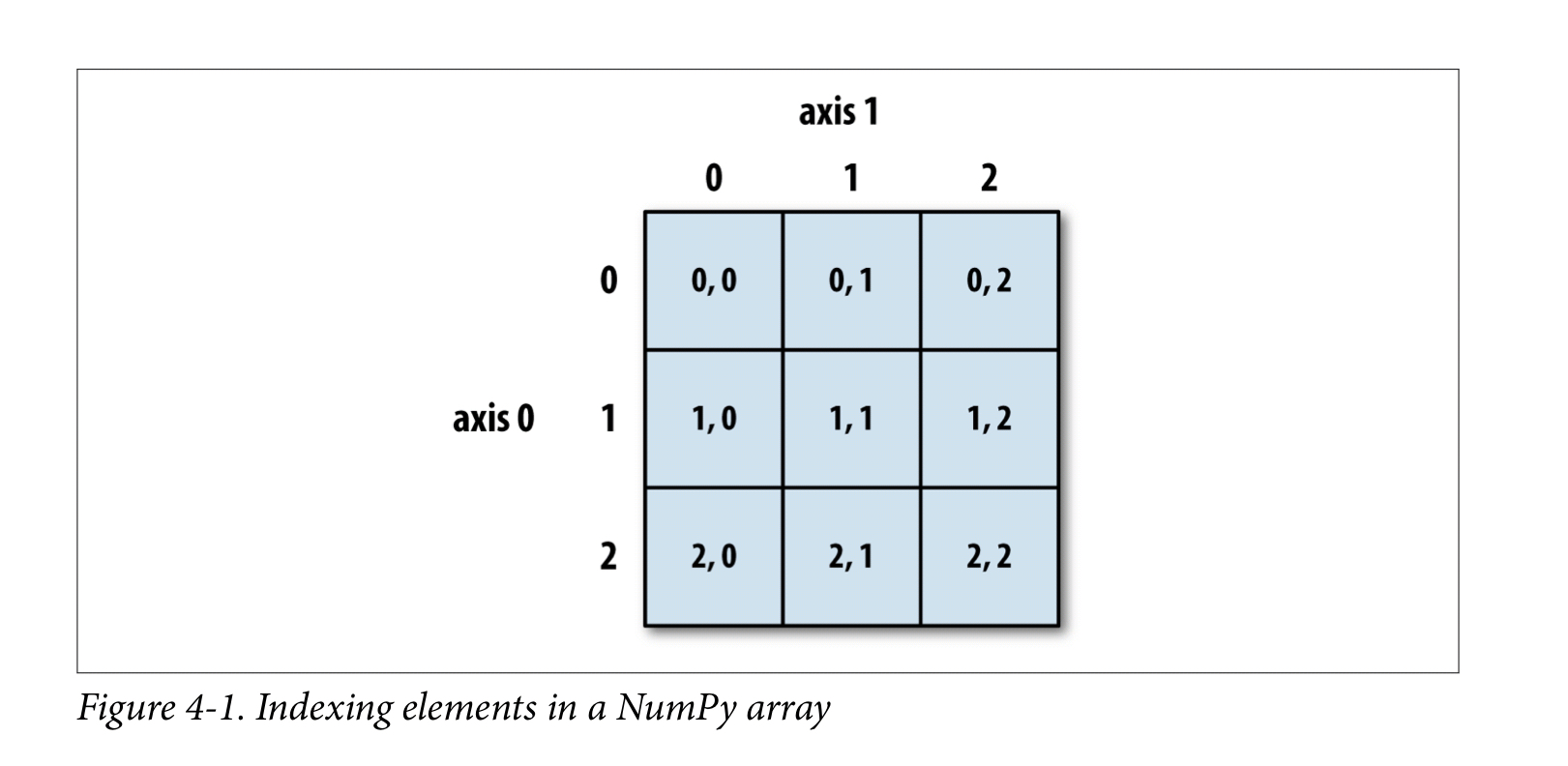
切片和索引
Numpy的切片和索引和数组的差不多,切片就是按照坐标或者坐标范围来找出对应,或对应范围内的值,根据坐标来理解就很简单
你可以对一个切片范围内的值重新赋值:
1 | arr = np.arange(10) |
np设计需要处理大量的数据,所以对于数组的操作,都是在原来的数据上改动,不会copy。
1 | arr_slice = arr[5:8] |
如果你要copy,np提供了一个copy函数:
1 | arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) |
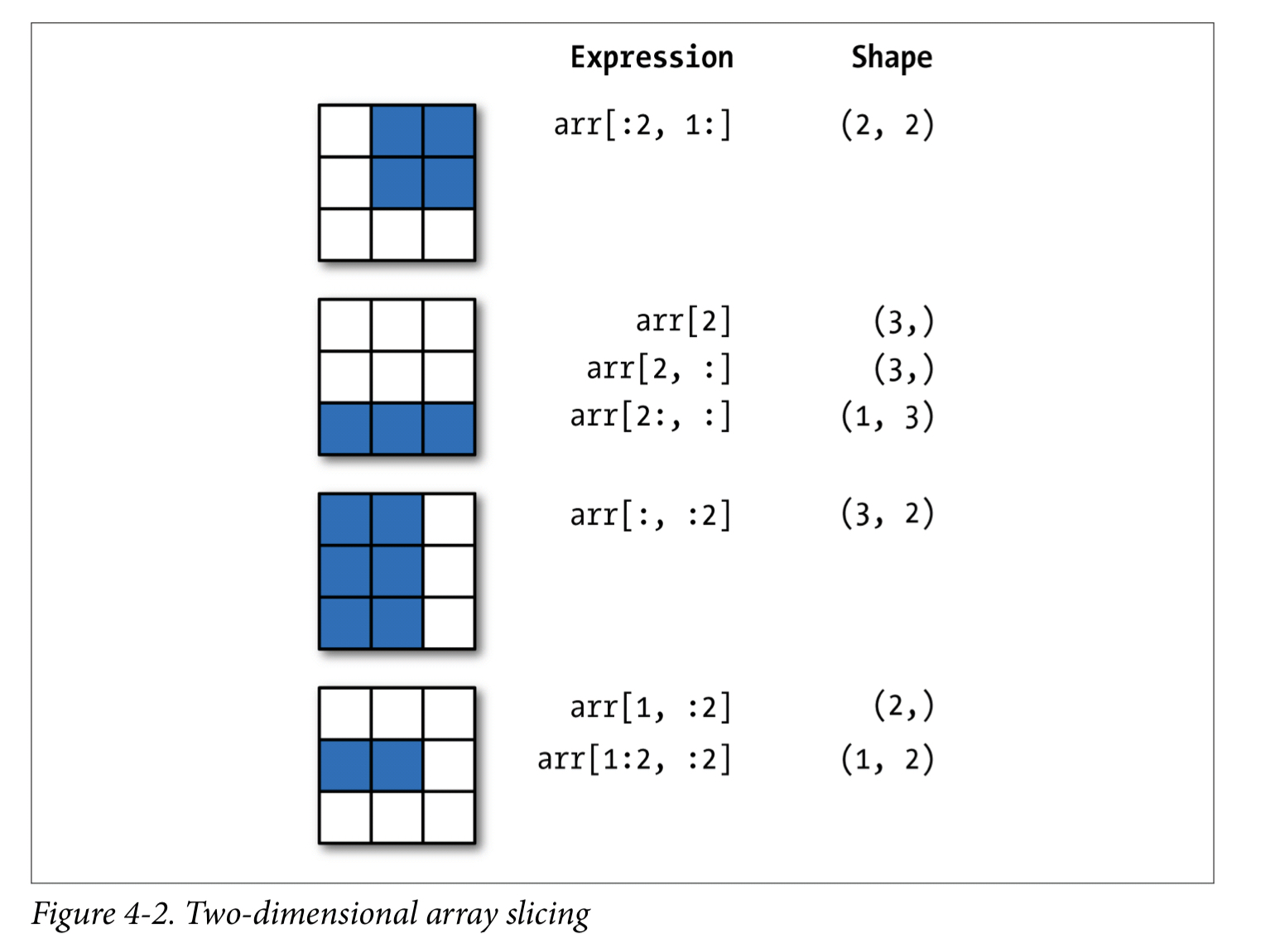
可以在两个维度上切片:
arr2d[:]
1 | array([[1, 2, 3], |
arr2d[:2]
1 | array([[1, 2, 3], |
arr2d[:2,1:]
1 | array([[2, 3], |
arr2d[:,:0]
1 | array([[1], |
参照下图,动手实践几次,就会懂其中的套路了。
Boolean Indexing
我们有一批名字:
1 | names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe']) |
我们可以直接通过 names == 'Bob' 来返回一个检查结果,这个结果包含的是一个 bollean 的 list.
names == 'Bob'
1 | array([ True, False, False, True, False, False, False], dtype=bool) |
如果我们有一份数据,也是7行,那么我们可以吧这个包含 True 和 False 的l List 传进去,这样 Numpy 会选出那些对应 True 的行。
data = np.random.randn(7,4)
1 | array([[-0.71030181, -0.14900916, -1.15238417, -0.49395683], |
data[names=='Bob']
1 | array([[-0.71030181, -0.14900916, -1.15238417, -0.49395683], |
Boolean selection will not fail if the boolean array is not the correct length, so I recommend care when using this feature.
上面的选择,也可以配合切片:
data[names=='Bob',:1]
1 | array([[-0.71030181], |
选择除了 Bob 之外的名字:
- names != 'Bob'
- ~(names == 'Bob')
对于 names 的过滤,可以用组合条件:
- cond = names == 'Bob'
- cond = (names=='Bob') | (names == 'will')
对于 data 也一样:
data[data < 0] = 0
设置整行的值也非常简单:
data[names != 'Joe'] = 7
1 | array([[ 7. , 7. , 7. , 7. ], |
Fancy Indexing
Fancy indexing is a term adopted by NumPy to describe indexing using integer arrays. Suppose we had an 8 × 4 array:
1 | arr = np.empty((8,4),dtype=np.int) |
选择单个值:
arr[3,0]
1 | out: 3 |
选择多行:
arr[[3,0]]
1 | array([[3, 3, 3, 3], |
让我们构建一个按顺序排列的 8x4 的数组:
arr = np.arange(32).reshape((8,4))
1 | array([[ 0, 1, 2, 3], |
按选择前两个子数组的第一个数:
arr[[1,2],[0,0]]
1 | array([4, 8]) |
你也可以对选择出来的数组,进行排序:
arr[[1,2]][:]
1 | array([[ 4, 5, 6, 7], |
arr[[1,2]][:,[0]]
1 | array([[4], |
arr[[1,2]][:,[0,3,2,1]]
1 | array([[ 4, 7, 6, 5], |
Fancy indexing always copies the data into a new array.
Transposing Arrays and Swapping Axes
Shape
1 | value = 18 |
1 | value = 18 |
只需要确保 Value = X * Y 就可以任意 shape 了。
Transposing
看例子:
arr = np.arange(18).reshape((3,6))
1 | array([[ 0, 1, 2, 3, 4, 5], |
arr.T
1 | array([[ 0, 6, 12], |
Transposing 在矩阵计算中用的非常多,比如用 np.dot 方法计算矩阵的内积:
1 | arra = np.array([2,3,0]) |
怎么计算内积?看下图就明白了