深入理解 Python 中的类与对象。
类和对象
对象是一个有着相应行为的数据的集合,比如苹果和橘子可以说都是对象。
假设我们在编写一个农场游戏,苹果会放到篮子里,橘子会放到桶中,那么现在就有四个对象。
对象和类有什么不同呢?类描述了对象,它们就像是创建对象的模板。
静态方法与类方法
理解方法是怎么工作的,Python 中的静态方法、类方法以及抽象方法,可以参考之前设计模式系列文章-单例模式及其实现原理。
type, object 和 class 的关系
type 有两种用法:一个是生成一个类;另外一个是查看某个对象的类型。
object 是所有类的基类,object 的基类是空, object 是 type 生成的。
但 type 本身也是一个类,同时 type 也是一个对象,type 的基类又是 object。
为了理解其中的关系,可以参考下图:
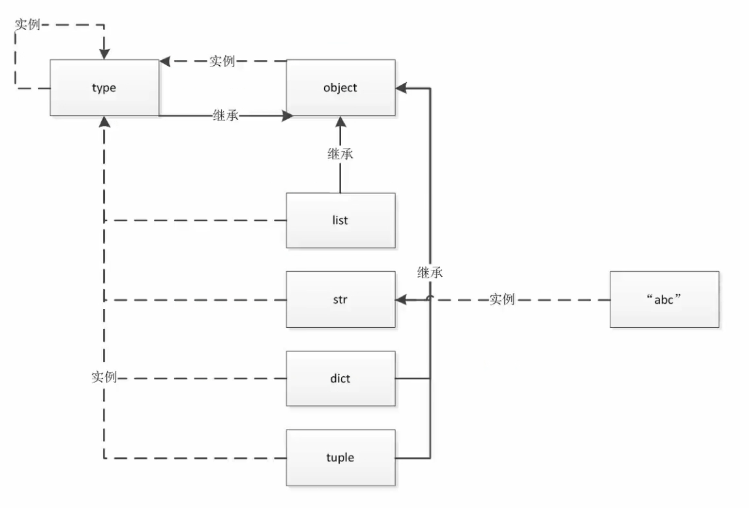 object, type and class
object, type and class
- 虚线描述的是实例关系,实线描述的是继承关系
- type 创建了所有的对象;type 继承自 object,而 object 又是 type 的一个实例;type 还是自己的实例(连自己都不放过);
举例:list 继承自 object,"abc" 继承自 str, str 又继承自 object;list类继承自 object 类,同时 list 也是 type 的一个实例对象,所以其实 list 既是类也是实例,即 python 中一切皆对象的一个理解。
为什么 list 是一个 class的同时,也要是一个对象,因为如果它变成一个对象,就可以动态的修改。而在静态语言中,类一旦创建放到内存中,修改起来就很麻烦了。而 python 中将其变成对象,就很简单了。
鸭子类型和多态
当你看见一只鸟走起来像鸭子、游泳像鸭子、叫起来也像鸭子,那么这只鸟就是鸭子。
1
2
3
4
5
6
7
8
9
10
11
12
| class Dog(object):
def say(self):
print('I am a dog')
class Duck(object):
def say(self):
print('I am a Duck')
for obj in [Dog, Duck]:
obj().say()
|
抽象基类
抽象基类,其他类可以继承此类,并必须要实现其规定的方法,抽象基类本身无法实例化出任何对象。
在 Python 中,检查某个类是否有某个方法,可以通过 hasattr 方法检查,比如:
1
2
3
4
5
6
7
8
9
10
11
| class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __len__(self, item):
return len(self.employee)
com = Company(['Apple', 'Google'])
hasattr(com, "__len__")
|
其结果与下面代码一致:
1
2
3
4
| from collections.abc import Sized
isinstance(com, Sized)
|
其中 Sized 是一个抽象基类。背后的逻辑是,com 实现了 __len__ 方法,所以它继承了 Sized 抽象基类,所以判断为真。
另外一种抽象基类的应用是限制子类必须实现某些方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class CacheBase():
def get(self, key):
raise NotImplementedError
def set(self, key, value):
raise NotImplementedError
class RedisCache(CacheBase):
pass
redis_cache = RedisCache()
redis_cache.get('test')
|
如果你希望在 RedisCache 初始化的时候就报错,则需要使用 abc 抽象基类模块。
1
2
3
4
5
6
7
8
9
10
11
12
| import abc
class CacheBaseABC(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self):
pass
@abc.abstractmethod
def set(self):
pass
redis_cache_abc = CacheBaseABC()
|
Python 中,abc 模块,有系统全局的abc,也有 collections.abc
在平时的编码实践中,注意不要过度依赖 abc 模块,容易导致过度设计, 可以考虑使用 mixin 的方式。
isinstance 和 type
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| class A:
pass
class B(A):
pass
b = B()
print(isinstance(b, B))
print(isinstance(b, A))
print(type(b) is B)
|
类变量与实例变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class A:
z = 0
def __init__(self, x, y):
self.x = x
self.y = y
a = A(1, 2)
print(a.z)
print(A.z)
print(a.x)
a.z = 99
print(a.z)
print(A.z)
A.z = 100
a = A(1, 2)
a.z
|
属性和查找顺序
属性分为类属性、实例属性。在上面的例子中,我们看到实例不存在的属性,在类中若可以找到则会被返回,这个查找顺序是怎样的呢?
简单的情况下,很容易理解,如果没有实例的 name 会使用类的 name,即 A。
1
2
3
4
5
6
7
| class A:
name = "A"
def __init__(self):
self.name = "obj"
a = A()
a.name
|
但如果是多继承是什么样的呢?比如下面的例子,A 是B, C, D, E的父类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
D E
| |
B C
\ /
A
# DFS 的搜索顺序
Deep First Search(DFS): A -> B -> D -> C -> E
D
/ \
B C
\ /
A
# DFS 存在的问题
这里的搜索顺序是A -> B -> D -> C
C 中有一个函数是重载 D 的,会导致无法重载
# 引入广度优先算法
对于图2,BFS: A -> B -> C -> D
对于图2,又有了新问题,假设 B,C,D 都有一个 get 方法
那么如果 B 找不到,广度优先会去 C 中找,C 的 get 就会覆盖 D 的
按理说应该 B 和 D 是一块
# 引入 C3 算法
# todo
在 python 中,可以通过 class.__mro__ 查看查找顺序
|
多继承
Python 也支持多线程,不过更推荐使用 Mixin 的模式。
本质上说就是让你的类继承自各种单一功能的类。可以简单理解为 java 中的函数,设计模式中的组合模式。
在设计 mixin 类的时候,尽量让它功能单一;不要让它和基类关联,这样就可以和任意基类组合;其次在 mixin 中,不要使用 super 这种用法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class ListDirMixin(object):
def list(self, *args, **kwargs):
pass
class ListFileMixin(object):
def list(self, *args, **kwargs):
pass
import minxin
class File(mixin.ListDirMixin, mixin.ListFileMixin):
pass
|
上下文管理器
首先通过两段代码来看 try except 在 Python 中的工作机制。
1
2
3
4
5
6
|
try:
raise KeyError
except KeyError:
print("KeyError")
|
try 还可以有其他的逻辑分支:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
try:
raise IndexError
except KeyError:
print("KeyError")
else:
print("Other Error")
finally:
print("Always run")
|
如果你用 python 打开一个文件,最后不管如何都需要关闭这个文件,你可能会在 try 中打开并读取文件, 然后在 finally 中关闭该文件。
这里有个问题是,如果你在 try 中打开文件之前报错了,那么在 finally 中则会无法关闭该文件,因为文件对象 还没来得及创建。
再来一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def try_test():
try:
raise IndexError
return 1
except IndexError:
return 2
else:
return 3
finally:
return 4
try_test()
|
with 语句的出现,可以简化我们的 try, finally 的使用。而 with 语句本身属于上下文管理器的一种实现,本质上来说,它遵从了一种类协议(实现了 2 个魔法函数).
这里涉及了两个魔法函数, __enter__, __exit__。(魔法函数将会在接下来的文章更新)
如果你实现了某个类的这两个函数,即实现了上下文管理器协议,你就可以使用 with 语句调用你的类,比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class Sample:
def __enter__(self):
print("enter")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("exit")
def do_something(self):
print("doing something")
with Sample() as sample:
sample.do_something()
|
你还可以通过 contextlib 进一步简化上下文管理器,这是 python 提供的内置模块, 它可以将一个 函数变成上下文管理器。
1
2
3
4
5
6
7
8
9
10
| import contextlib
@contextlib.contextmanager
def file_open(file_name):
print("open a file")
yield {}
print("exit logic")
with file_open("file.txt") as f_opend:
print("processing...")
|
