Spark 概述、浅析、工具集与结构化API。
Spark 指南
大数据与 Spark 概述
Spark 浅析
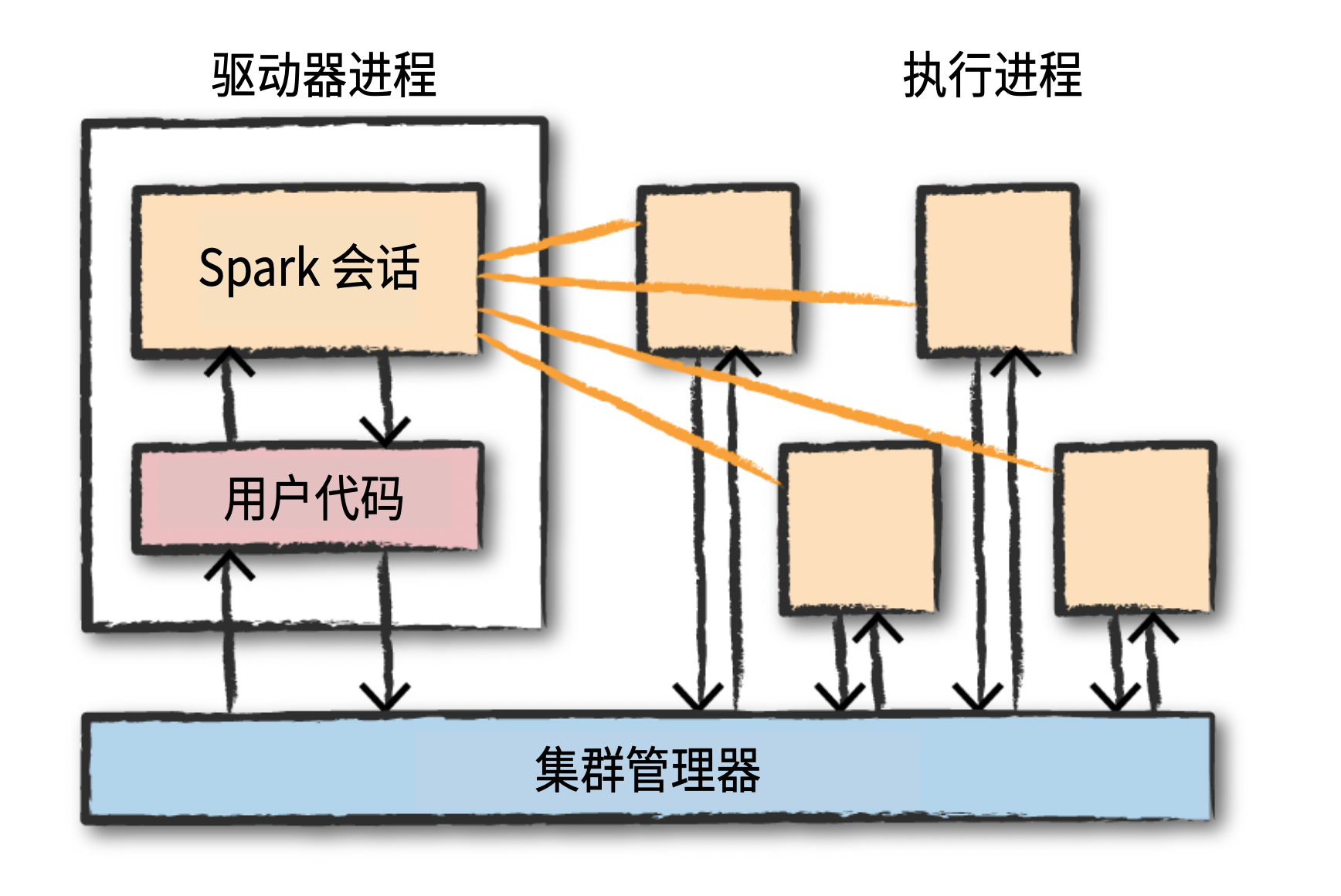
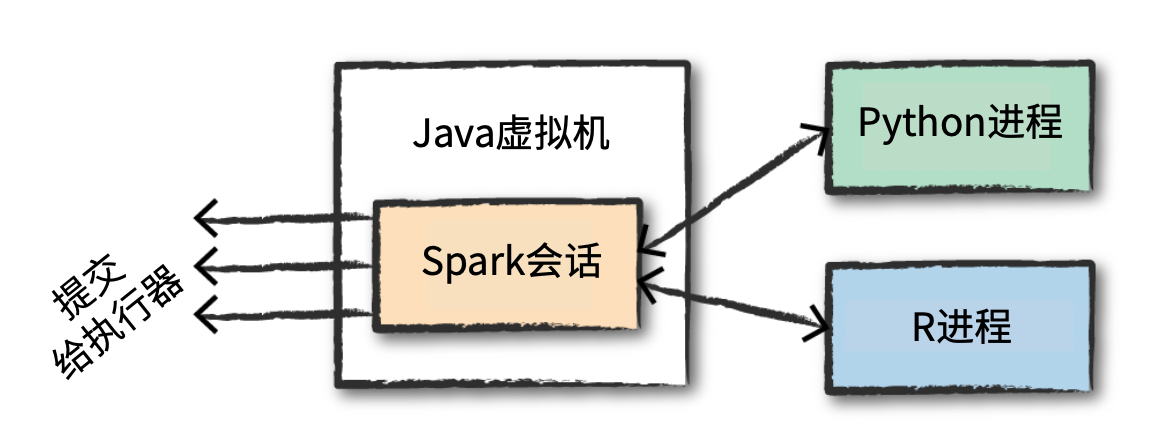
多语言支持中通过 spark 会话提交任务给执行器,具体如下图所示:

Spark 工具集介绍

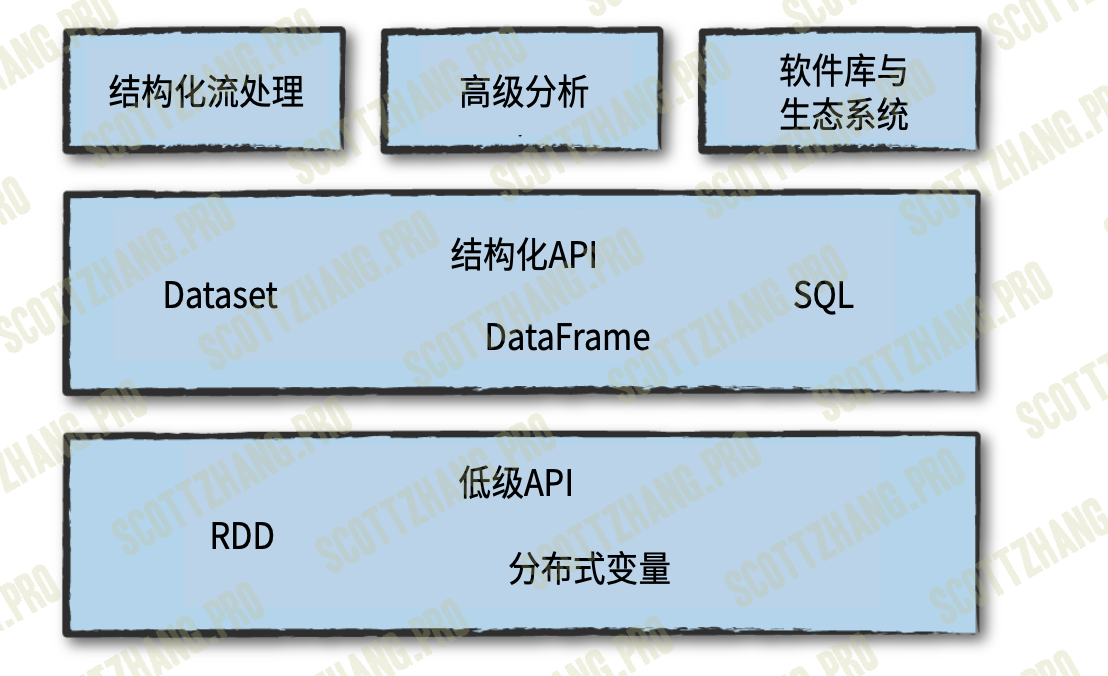
结构化 API
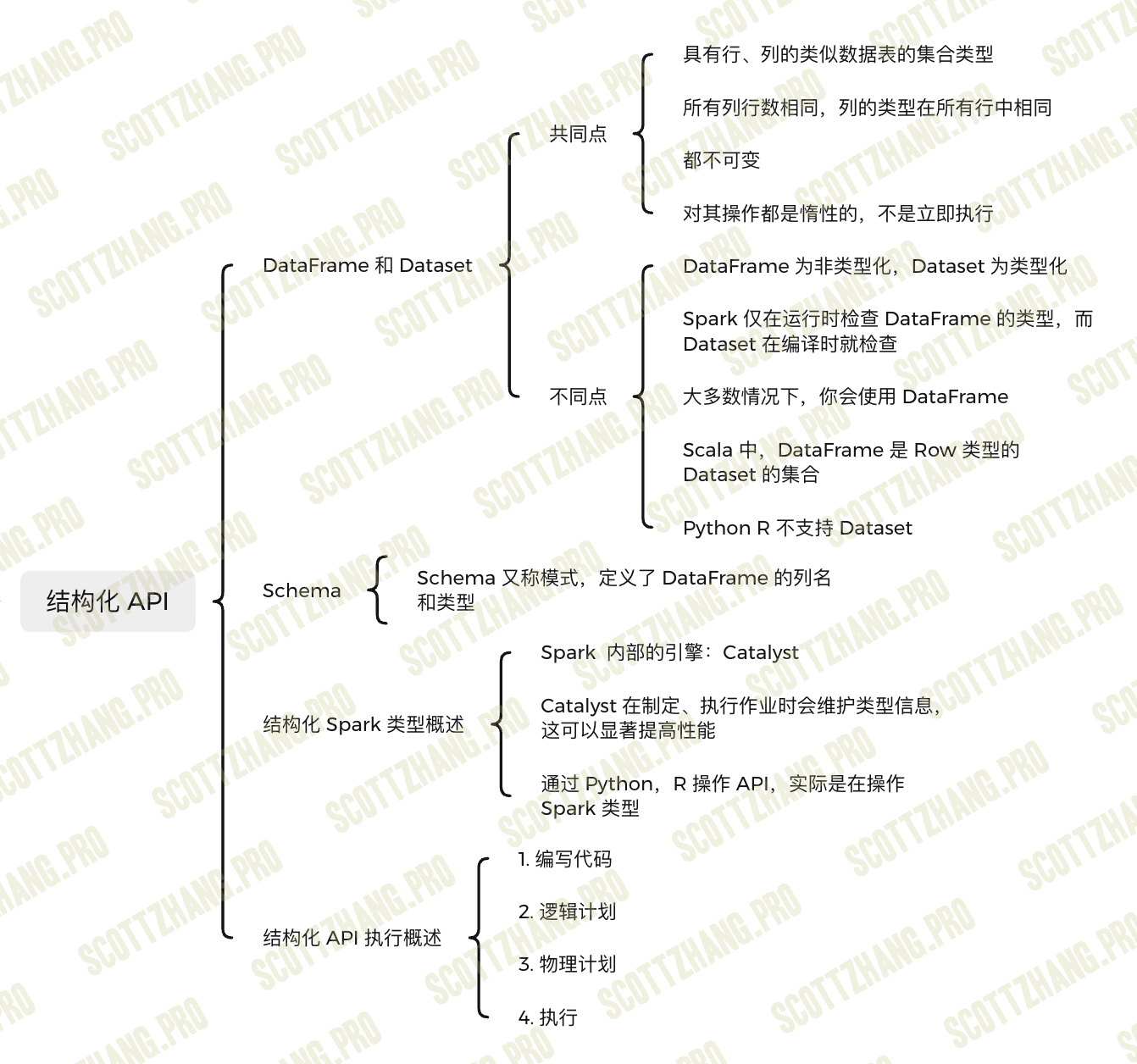
结构化API指以下三种核心分布式集合类型的API: - Dataset类型。 - DataFrame类型。 - SQL表和视图。
结构化API是在编写大部分数据处理程序时会用到的基础抽象概念。
结构化API的执行步骤
- 编写DataFrame / Dataset / SQL代码。
- 如果代码能有效执行, Spark将其转换为一个逻辑执行计划(Logical Plan)。
- Spark将此逻辑执行计划转化为一个物理执行计划(Physical Plan), 检查可行的 优化策略,并在此过程中检查优化。
- Spark在集群上执行该物理执行计划(RDD操作)。
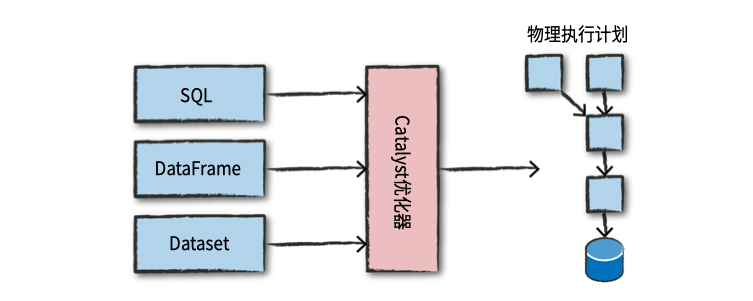
通过控制台提交给Spark,或者以一个Spark作业的形式提交。然后代码将交由Catalyst优化器决定如何执行, 并指定一个执行计划。 最后代码被运行, 得到的结果返回给用户。图4-1展示了整个过程。
逻辑计划
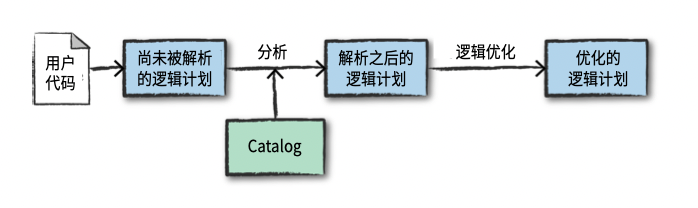
Spark使用catalog(所有表和DataFrame信息的存储库)在分析器中 解析列和表格。 如果目录中不存在所需的表或列名称, 分析器可能会拒绝该未解析的 逻辑计划。
物理计划
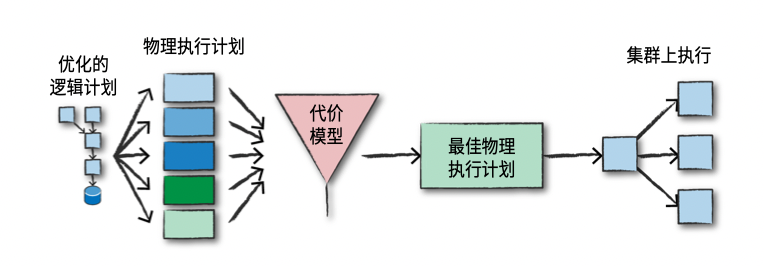
在成功创建优化的逻辑计划后, Spark开始执行物理计划流程。物理规划产生一系列的RDD和转换操作。 这就是Spark被称为编译器的原因, 因为它 将对DataFrame、Dataset和SQL中的查询来作为你编译一系列RDD的转换操作。
执行
在选择一个物理计划时, Spark将所有代码运行在Spark的底层编程接口RDD上(第Ⅲ 部分将会介绍)。 Spark在运行时执行进一步优化, 生成可以在执行期间优化任务或 阶段的本地Java字节码,最终将结果返回给用户。
