如何根据jira工单的category自动找到处理它的组呢?这是一个利用机器学习中knn算法的小实践.
算法
我们使用knn分类算法,knn是广为使用的一种机器学习算法,应用于各种应用,如金融、医疗保健、政治学、手写字识别、图像识别与视频识别。
在信用评级中,金融机构用来预测客户的信用评级。在贷款支付机构中,银行来预测贷款是否安全。在政治中,它被用来预测潜在选名是否会投票。
简单介绍下knn:
knn是non-parametric算法,即无假设的意思,它不会对基础数据的分布做任何假设,即不会根据数据集来确定模型结构。
这很有用,因为在现实世界中,很多的数据集是不遵从数学理论的假设的。
同时knn是lazy algorithm算法,即它不需要在模型建立前做大量的数据训练工作。
数据
我们已经把一些数据保存到了jira数据库,现在将它们的分类与所属组拿出来:
1 | sql = select category,assign_group from issues limit 10000 |
现在数据已经保存到了df中。
A basic Exapple
单个features
1 | from sklearn import preprocessing |
多个features
另外一种方式,x是我们的category,y则是所属组。
1 | from sklearn.neighbors import KNeighborsClassifier |
随后你可以直接将x_train传给knn做个预测,然后跟真实的数据做个对比。
拿训练的数据来做预测是不可取的,你必须给模型一些它从来没有看见过的数据预测,这样才能准确的测试模型的性能
你也可以自己生成一些数据来查看,如你已经知道get_dummies后的df有144列,那么你可以自行生成一个2d的dummie数组传给knn.predit.
1 | arr_list = np.concatenate(np.zeros((1,143))) |
1 | output: array(['Helpdesk CN']) |
分割数据并查看得分
下面演示了将数据拆分成train,和test后的预测分数:
1 | X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42) |
1 | output:0.781 |
78%,这个模型效果还是不错的!
选择Neighbors
我们知道对于knn算法,其中一个关键的参数是neighbors,那么对于不同的neighbors,我们的accuracy的分数是什么样的呢?我们可以来画个图检测一下:
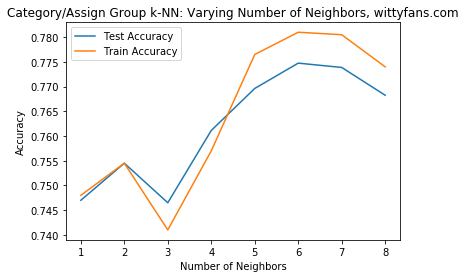
可以看到neighbors在6-7之间,accuracy是最高的,在2-5之间,test的得分竟然比训练数据都要高。
使用knn的优缺点
- knn算法对于处理非线性数据很有用,可以用它一起处理回归问题
- knn的测试阶段较慢且耗资源,需要很多的内存来保存来预测的整个数据集
- 强烈建议将数据进行同比例的标准化,比如将所有数据缩放到0,1的区间内
- knn不适合太高维度的数据,在那种情况下,需要将维度降低
- 处理缺失值有助于改善模型的准确度
问题
1. knn fit其中的x,x一定只能是get_dummies算出来的数据吗?
不是,比如 iris 的数据摘要,X的数据是各个部分的长、宽:
1 | [[5.1,3.5,1.4,0.2], |
2. knn fit其中的y,y可以是原始数据类型吗?如a,b,a,c
可以,如 datacamp 题目中的政党数据,y=df['party']:
1 | Out[8]: |
